
XLOG与MMKV
内容概要:本篇文章介绍XLOG、MMKV的原理,以及将其引入到项目中的效果和需要注意的问题。
一、XLOG原理
在介绍XLOG原理之前,我想介绍下为什么我们需要XLOG?原生Android写日志有哪些缺点?
首先,原生Android写日志的内容较少。这里的少有两个方面,一方面是原生写日志只能写我们传递给他的内容,最多再加上时间和tag。另一方面是为了不过度影响用户手机的内存,我们规定日志只能存储2M的空间,这就使得之前的日志可能被清除掉,不便于我们定位问题,如果我们要再压缩日志文件,就会影响到性能。其次,原生的Anroid写日志速度较慢。为什么速度慢呢?我们来看下Android直接写文件的原理。

待写的内容首先需要从用户空间内存拷贝到内核空间内存,再从内核空间拷贝到文件中。这里需要回答两个问题,为什么linux里面需要区分用户和内核空间,第二为什么两个空间的切换需要耗时。第一个问题,linux系统为了让有限的资源得到更大化的利用,并为了防止资源被冲突访问,引入了一个”特权阶级”,也就是内核空间,只有该特权阶级才可以访问资源。第二个问题,当我们写日志时,首先需要保存现场,将现场的内容传输给内核空间,由于内核空间是”特权阶级”,我们要保证他的安全性,这就需要详细检查传输的内容是否有问题,没有问题后再恢复现场并交给内核空间。上面提到的保留现场、检查、恢复现场就导致了两个空间切换的耗时,也就导致了原生写日志的耗时。
再来看下XLOG的写日志,XLOG写日志是通过mmap来写的。
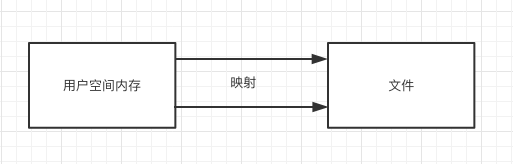
mmap就是将资源直接映射到用户空间内存,跳过了我们上面提到的”特权阶级”。也就避免了两个空间切换的开销。我们可以通过直接操作内存来完成对文件的读写。而日志从内存回写进文件的机制是crash、内存不足、主动回写。这就避免了因为App崩溃、内存不足等问题带来的日志丢失问题。
XLOG写日志时,为了保证日志内容在mmap中不被窥探到,采用了先加密,后写入mmap内存中的机制。

而为了保证加密的效率,采取的是先压缩后加密的方式。更具体的说XLOG是采用的单行逐个压缩的方式,对比多行同时压缩,虽然速度上慢了一些,但是也只是微秒级别的慢。而多行同时压缩还会带来短时间内cpu使用率突然变高的问题,这就导致了App的卡顿。
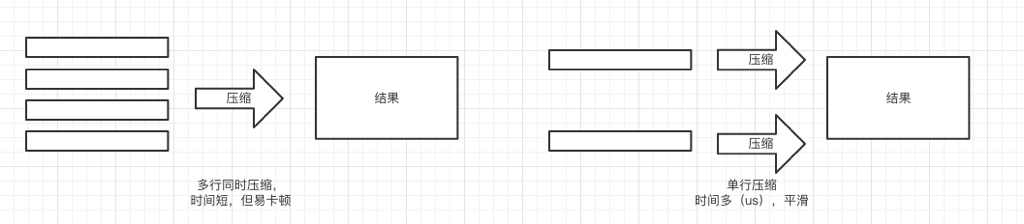
因此XLOG选择了单行压缩的方式,将压缩过程延展到整个App的周期,避免了卡顿的问题。
XLOG的压缩,采用的是短语压缩和哈夫曼编码的方式,短语压缩针对的是字符串,哈夫曼压缩针对的是数字。
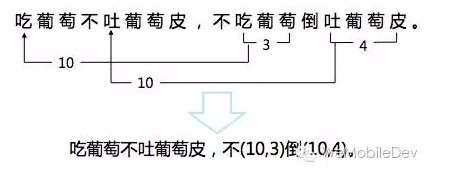
这里是一个官方的例子,吃葡萄不吐葡萄皮,不吃葡萄倒吐葡萄皮。经过短语压缩后,就变为了吃葡萄不吐葡萄皮,不(10,3)倒(10,4)。
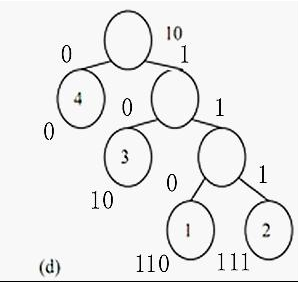
而哈夫曼编码则是根据数字出现的次数构建一个二叉树,如这里的4,3,1,2分别压缩为0,10,110,111。
此外,XLOG的日志内容还可以定制,我们可以打印出日志所属的类、方法、行号。以及日志所属线程的ID、主线程ID等。
二、引入XLOG带来的效果和问题
首先是效果,在项目中同时使用原生LOG和XLOG,进行写日志,经过5分钟后,原生LOG需要花费240ms,而XLOG只需要80ms
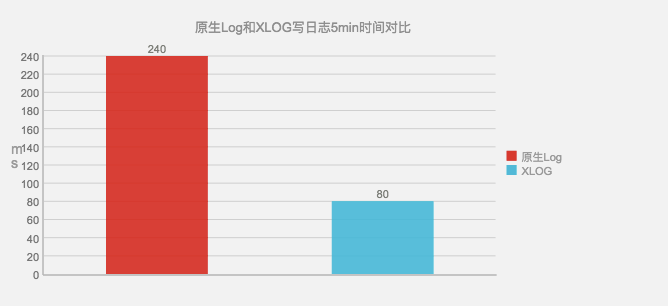
那么我们使用XLOG后,由于其压缩的特性,我们需要使用python2.7进行解压。并且由于其默认只记录10天的日志数据,更早的问题我们是无法定位的。另外一点是每次启动时都会检查日志是否满,如果满了就要进行清除。
三、MMKV原理
同样,我们为什么要引入MMKV,原生的SharedPreferences有什么问题呢?问题还是速度,因为原生的sp的commit操作是同步的,其中还涉及XML到string的转换,并且存在上面的写文件时的两个空间的切换开销,这就导致速度变慢。
我们来看下SharedPreferences一次写的过程

首先需要写的内容存入文档对象模型,也就是XML中,然后XML转换为字符串,再拷贝到文件中,这里有两个方面的开销,一个是文档对象模型与string的转换,一个是调用原生存接口,存入文件。
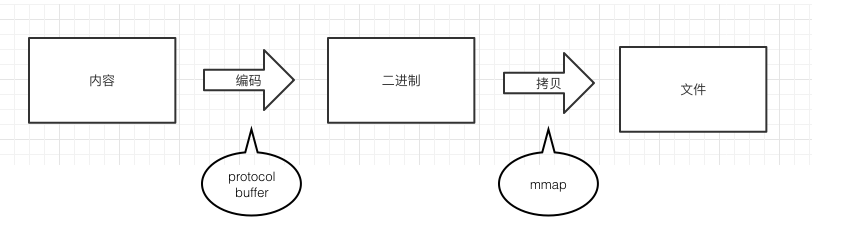
而MMKV,则是将内容使用protocol buffer编码为二进制,再对二进制使用mmap存入文件中。这里的编码只是使用二进制位移等操作,速度快。
我们来具体看下protocol buffer这个协议,他对不同的类型,使用不同的编码方式,对正数使用variant,对负数使用zigzag。对fixed64使用64-bit。对string、bytes等使用Length-delmi。
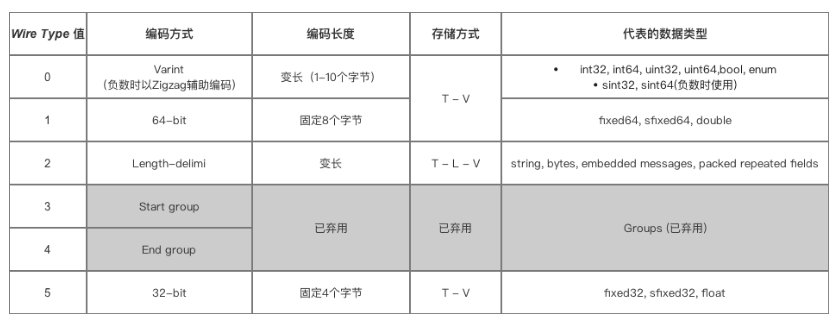
虽然使用不同的编码方式,但都转换为
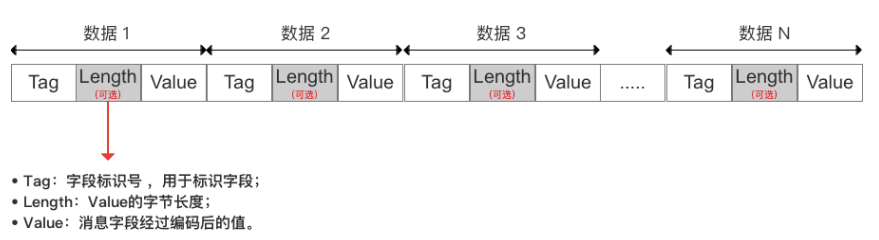
T-L-V,这种tag-length-value的形式。
这里我以zigzag这个编码方式为例,来介绍一下protocol buffer是如何高效的编码,并且压缩率很好的。
首先针对数字-1,他的原码
-1=(10000000_00000000_00000000_000000001)(原码)
为了记录-1,我需要用32位去表示。无法压缩中间的0
-1的反码和补码是
-1=(11111111_11111111_1111111_11111110)(反码)
-1=(11111111_11111111_1111111_11111111)(补码)
可以看到,无论原码、反码、补码都是需要32位去表示一个-1,这种方式很明显,我们无法进行有效的压缩。
zigzag的做法就是将符号位移动到最后一位,
(-1)= (11111111_11111111_11111111_11111111)补
= (11111111_11111111_11111111_11111111)符号后移
但是这样我们还是无法有效压缩,我们就考虑处理数字位,因为负数的数字越小,1就越多,就考虑将数据位全部取反:
= (00000000_00000000_00000000_00000001)zigzag
变成只有第一位为1,这样我们就好压缩。
同样,针对正数,先将数据位前移,再将符号位移动到第一位。
(1)= (00000000_00000000_00000000_00000001)补
= (00000000_00000000_00000000_00000010)符号后移
= (00000000_00000000_00000000_00000010)zigzag
然后,我们只需要想一种方式,将正数和负数的处理方式统一就可以,
zigzag是这样做的,先将-1,连符号位左移一位,后面补0
-1=(11111111_11111111_1111111_11111111)(补码)
=》
(11111111_11111111_1111111_11111110)
再将原先的值符号位右移31位,最高位补符号位
-1=(11111111_11111111_1111111_11111111)(补码)
=》
(11111111_11111111_1111111_11111111)
最后再将两者异或,得到结果
=00000000_00000000_00000000_00000001
这样我们就可以处理压缩前面的1
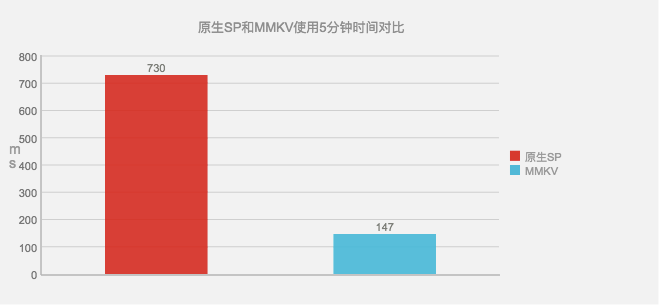
项目中同时使用原生SharedPreferences和MMKV,进行退出登录、再登录等操作五分钟后,原生SP需要730ms的开销,而MMKV只需要147ms的开销。
在迁移过程中,我们直接使用官方提供的迁移函数即可,原先的SP操作只要从sharedPreferenecs类更换为MMKV类,具体put、get、editor等方法不需要更改。另外一个就是MMKV是调用函数立即生效,就不需要原先的commit操作了。
为了将项目迁移到MMKV上,还需要一个判断是否迁移的函数。目前我的处理是老版本升级到新版本才迁移,初次安装新版本以及安装新版本后的更新都不需要迁移。